
Ça y est, votre tableur est paré, vous êtes prêt(e) à commencer votre recueil ? Pas si sûr ! Avant de partir tête baissée, il est urgent de vérifier si votre tableur ne comporte pas de graves anomalies qui pourraient vous faire perdre un temps précieux.
Concrètement, quels sont les risques ?
Lors d’un premier travail de recherche, il est normal de ne pas savoir exactement comment formater son tableur. Le risque, c’est de passer un temps considérable à le remplir pour arriver à la fin à un recueil qui n’est pas exploitable en l’état. Certes, vos données seront bien là, mais sans certaines précautions, vous pourriez ne pas pouvoir les analyser avec un logiciel de statistique.
Alors plutôt que de tout recommencer, il vaut mieux partir dès le départ avec un tableur qui tient la route.
Les erreurs à ne pas commettre
De façon globale, il est conseillé de faire relire son tableur vierge avant tout recueil par un statisticien afin de s’assurer que tout est en ordre.
Des lignes et des colonnes
Commençons par la base : un tableur de recueil, c’est UNE colonne par variable, UNE ligne par sujet. Surtout pas l’inverse ! La première ligne servira à renseigner les noms des variables.
Pourquoi ? Les logiciels de statistique se basent toujours sur cette norme. Importer un tableur qui ne le respecte pas ne fonctionnera pas.
Séparer ses groupes en différents feuillets/tables
Vos sujets sont répartis en groupes A, B, C et tout naturellement, vous aimeriez les répartir en trois feuillets différents ? STOP ! Le groupe n’est qu’une variable parmi d’autres. Tous vos sujets doivent être dans la même table. Vous inscrirez simplement A, B ou C dans la colonne groupe pour les différencier. Voici un exemple de ce qu’il faut faire :
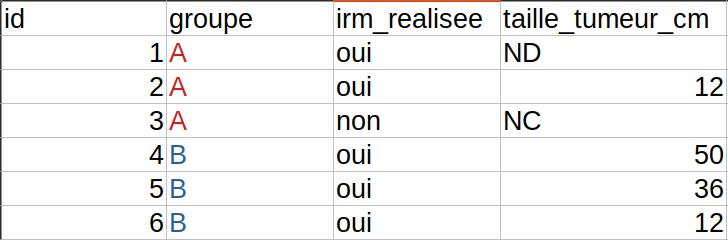
En multipliant les tables, vous prenez le risque d’avoir des colonnes qui ne sont pas tout à fait identiques entre chaque version. L’import dans un outil d’analyse statistique sera beaucoup plus compliqué.
Faire usage de la couleur
Rien n’interdit de colorer des cellules ou du texte dans votre tableur. Cela peut même en améliorer la lisibilité. Sachez cependant que cette information n’est pas exploitable par les outils d’analyse statistique. La couleur ne doit donc avoir qu’un rôle esthétique dans votre recueil.
Cas fréquemment rencontré : vous colorez en rouge les sujets (lignes) à exclure de vos analyses. Préférez plutôt l’ajout d’une colonne « exclusion » dans laquelle vous placerez un oui/non (ou équivalent). Vous pourrez ensuite filtrer sur ce critère dans votre logiciel d’analyse statistique.
Ne pas tenir compte du format de date
Les tableurs tels que Microsoft Excel ou LibreOffice Calc peuvent avoir des comportements effroyables avec les dates. Selon votre installation, le format de date paramétré par défaut pourra être JJ/MM/YYYY (français) ou MM/JJ/YYYY (américain).
Si par malheur le format américain est paramétré et que vous ne faites rien, vous allez au-devant de grandes complications. Imaginez le scénario suivant :
- Vous renseignez la date « 02/10/2024 » pensant inscrire le 2 octobre 2024. Votre tableur, lui, a enregistré cette date comme étant le 10 février 2024, mais affiche toujours 02/10/2024 ce qui ne laisse rien présager.
- Vous poursuivez jusqu’à inscrire une date telle que « 18/04/2020 ». Votre tableur ne comprend pas cette date (le 18e mois n’existant pas) et vous le fait subtilement remarquer en décalant cette valeur sur la gauche.
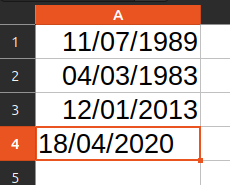
- Dans le meilleur des cas, vous vous en apercevez et décidez de changer le format de date. Pour cela, vous sélectionnez la colonne comprenant vos dates, faites un clic droit > Format, puis sélectionnez un format « Date » sous la forme « 31/12/1999 » (JJ/MM/AAAA). Hélas, cela ne résout en rien le problème. Le format d’affichage est corrigé, mais toutes les dates saisies ont été interprétées de façon erronée. Il ne vous reste plus qu’à tout recommencer.
Avant/après changement de format de date : ⇉ 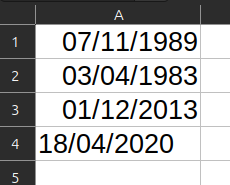
- Dans le pire des cas, vous n’avez pas vu cette subtilité. Au moment d’importer votre tableur dans votre logiciel d’analyse statistique, ce sont les dates erronées qui seront prises en compte. Vos résultats pourraient être totalement faussés par ce comportement.
La solution : Paramétrez le format des colonnes dates dès la conception de votre tableur. Choisissez le format ISO : AAAA-MM-JJ. Ce format ne présente aucune ambiguïté entre les jours et les mois car il n’existe pas de format AAAA-JJ-MM.
Recueillir en texte libre / stocker plusieurs informations dans une même cellule
Une cellule ne doit contenir qu’une seule information. Il peut s’agir :
- d’une date, d’une heure, voire d’une date + heure
- d’un nombre entier ou décimal (sans unité)
- d’un binaire (oui/non, Y/N, 1/0, etc)
- d’une catégorie (ex : A/B/C/D, rouge/vert/bleu)
- d’une valeur manquante (NA/ND ou NC ⇾ voir plus loin)
- et RIEN D’AUTRE !
Tout autre contenu ne sera pas exploitable sans transformation préalable lors de l’analyse statistique.
Voici quelques cas classiques :
- âge pédiatrique : on exprime souvent l’âge sous des formes telles que « 2 mois 7 jours » ou « 1 an 3 mois ». Vous devez convertir cet âge en un nombre sans unité. Pour cela, choisissez une unité (ex : le jour) et convertissez tous les âges vers cette unité
- antécédents/médicaments : lorsqu’on recueille une liste d’antécédents, on est parfois tentés de mettre l’ensemble de ces informations dans une même cellule, séparées par une virgule. A la place, considérez que chaque antécédent ou médicament est une variable binaire (présent/non présent). Créez donc autant de variable que d’antécédent/médicament et renseignez le statut dans chaque colonne
- motif d’hospitalisation (ou plus largement tout texte libre). En l’état, ces textes ne pourront pas être exploités. Vous devrez créer des catégories et donc une/plusieurs variables dans lesquelles reclasser le motif. Exemple : tous les motifs comportant le mot fracture seront renseignés avec la valeur « oui » dans la variable « motif_traumatologie ». Vous pouvez éventuellement recueillir ces textes libres dans votre tableur, mais devrez donc les retravailler pour les rendre exploitables.
Discrétiser vos variables quantitatives
Lorsque vous recueillez une variable quantitative, renseignez sa valeur exacte. Même si vous prévoyez plus tard de discrétiser cette variables en plusieurs classes.
Par exemple : vous souhaitez recueillir l’âge de vos patients et envisagez de présenter dans vos résultats les effectifs pour différentes classes d’âge : [18 ; 25), [25 ; 40) et 40 ans et plus. Si vous renseignez directement la classe d’age dans voter tableur, vous vous privez des possibilités suivantes :
- vous ne pourrez pas redécouper vos âges en différentes classes si vous changez d’avis
- vous ne pourrez pas calculer de statistiques telles que la moyenne d’âge, sa médiane, écart type, Q1-Q3, etc
-> Conservez la valeur exacte au recueil et appliquer une discrétisation dans une colonne à part si besoin.
Nommer vos variables « comme ça vient »
Les noms de variables doivent être courts et explicites pour plus de lisibilité. Et idéalement doivent suivre une convention de nommage, car cela facilite grandement la manipulation des données lors de l’analyse statistique. Certains logiciels vont même jusqu’à refuser l’import si vous ne respectez pas la convention.
Avec TablR, vous êtes libres de nommer vos variables comme bon vous semble.
Voici deux conventions de nommage couramment employées et appliquées à la variable « Durée de traitement en mois« :
| Convention | Résultat |
| snake_case | duree_traitement_en_mois |
| PascalCase | DuréeTraitementEnMois |
- supprimer tout accent ou caractère spécial (cédille, ponctuation, apostrophe)
- réduire au maximum l’emploi d’articles (duree_
de_traitement) - ne pas commencer un nom de variable par un nombre
Pseudo-coder toutes mes données
Par le passé, on conseillait de systématiquement remplacer vos données catégorielles par un court code. Par exemple pour une variable « pays de naissance », vous pourriez recoder les valeurs comme suivant :
- France ⇾ F
- Allemagne ⇾ A
- Espagne ⇾ E
- etc
Cette pratique était obligatoire afin de réduire la taille des fichiers à une époque où nos ordinateurs n’étaient pas aussi puissants. Cette pratique n’est plus obligatoire. Vous pouvez au choix :
- soit pseudo-coder tout ou partie de votre tableur. La saisie sera plus rapide, mais la relecture parfois plus difficile. Mais dans ce cas, veillez impérativement à tracer la correspondance de vos codes dans un fichier à part ou un onglet de votre tableur.
- soit conserver les libellés entiers lors du recueil. Soyez cependant vigilants à toujours orthographier vos libellés de la même façon : FRANCE et France seront traités comme deux pays distincts lors de l’analyse statistique.
On conseillait également de saisir toutes les variables binaires (oui/non) sous forme de 1/0. Là encore, vous êtes libre de pseudo-coder ou non.
Laisser des cellules vides
Lorsque vous n’avez pas de valeur à saisir dans une cellule, cela peut être pour deux raisons :
- Cette information n’est pas disponible (donnée manquante) ⇾ dans ce cas, renseignez NA (pour Not Available) ou ND (pour Non Disponible)
- Le sujet n’est pas concerné par cette variable. Imaginez que vous recueillez les variables « scanner réalisé » et « diagnostic au scanner ». Si vous avez renseigné « non » dans la première variable, le sujet n’est pas concerné par la 2e ⇾ dans ce cas, renseignez NC (pour Non Concerné / Not Concerned)
En procédant de la sorte, vous êtes certain(e) que toutes les cellules encore vides sont des informations qui doivent être recherchées. Pratique pour savoir où vous en êtes ! Pour plus d’informations, consultez notre article dédié à la saisie des valeurs manquantes.
Mais est-ce que ça ne vas pas poser problème au moment de l’analyse ces NA/ND/NC partout dans votre tableur ? Non rassurez-vous, il y a 2 scénario :
- Votre logiciel d’analyse statistique prend en charge les valeurs manquantes. Dans ce cas il suffit de lui lister les termes employés (NA/ND/NC) pour déclarer ces valeurs lors de l’import de votre tableur.
- Votre logiciel ne le prend pas en charge, créez une copie de votre tableur une fois le recueil terminé. Puis dans cette copie, remplacez tous les NA/ND/NC par une chaîne de caractères vide (CTRL+H sous Microsoft Excel et LibreOffice Calc).
Et surtout : vérifiez par vous-même !
Pour être certain que vos données seront importées correctement dans votre outil statistique, le plus simple est encore de renseigner quelques lignes de données fictives dans votre tableur, puis de tenter de l’importer.
Vérifiez alors que vos variables sont bien reconnues, que leurs types (quantitatif ou qualitatif) sont correctement identifiés, ou encore que vos valeurs manquantes sont bien identifiées en tant que tel.
Envie d’un outil statistique simple et rapide d’utilisation ? Essayez TablR
Importez votre fichier en 3 clics et vérifiez que votre tableur est conforme

