Préparer son tableur de recueil de thèse : les erreurs à éviter
Une checklist concrète pour construire un tableur de recueil exploitable avant de commencer une thèse de médecine.
Un tableur de recueil de thèse peut sembler prêt parce que ses colonnes sont créées. En pratique, c’est souvent là que les problèmes commencent : dates mal interprétées, groupes séparés dans plusieurs onglets, cellules vides, couleurs utilisées comme information, variables impossibles à analyser.
L’objectif n’est pas de faire un beau fichier. L’objectif est de produire une base exploitable pour les statistiques, la rédaction des résultats et, si besoin, la relecture par un statisticien.
Si vous n’avez pas encore choisi votre outil, commencez par l’article sur le choix de l’outil de recueil de données. Si vous êtes déjà parti sur Excel, LibreOffice Calc ou un équivalent, cette checklist vous permet de vérifier votre tableur avant de recueillir les premières vraies données. Elle s’inscrit dans la section recueil de données du guide complet de la thèse de médecine.
Pourquoi vérifier son tableur avant le recueil ?
Lors d’une première thèse de médecine, il est normal de ne pas savoir exactement comment structurer une base. Le risque est de passer plusieurs semaines à remplir un fichier, puis de découvrir au moment des analyses qu’il n’est pas exploitable sans nettoyage lourd.
Les données sont parfois bien présentes, mais sous une forme difficile à utiliser :
- une information est répartie sur plusieurs colonnes ;
- plusieurs informations sont stockées dans une même cellule ;
- les dates ont été interprétées dans le mauvais format ;
- les groupes sont dans plusieurs onglets ;
- les valeurs manquantes ne sont pas distinguées des oublis de saisie ;
- les noms de variables sont trop longs, ambigus ou incompatibles avec certains logiciels.
Dans le doute, faites relire votre tableur vierge avant le recueil. Un échange précoce avec votre directeur, un méthodologiste ou un statisticien est beaucoup plus efficace qu’une correction tardive. C’est particulièrement vrai si vous comptez faire appel à un expert pour les statistiques de thèse.
La règle de base : une ligne par sujet, une colonne par variable
La structure attendue par la plupart des outils statistiques est simple :
- une ligne correspond à un sujet, un patient, un séjour ou une unité d’analyse ;
- une colonne correspond à une variable ;
- la première ligne contient les noms des variables ;
- chaque cellule contient une seule valeur.
Pour une thèse rétrospective sur dossiers patients, une ligne peut représenter un patient. Pour une étude sur des séjours hospitaliers, une ligne peut représenter un séjour. Le point important est de choisir l’unité d’analyse avant de commencer et de ne pas la changer en cours de recueil.
Exemple de structure correcte :
| id_patient | groupe | age_annees | sexe | scanner_realise | diagnostic_scanner |
|---|---|---|---|---|---|
| 001 | A | 64 | F | oui | fracture |
| 002 | B | 72 | M | non | NC |
| 003 | A | 51 | F | oui | normal |
Cette structure est moins agréable à lire qu’un tableau “présentable”, mais elle est beaucoup plus facile à analyser.
Les erreurs qui rendent un tableur difficile à analyser
1. Séparer les groupes en plusieurs feuilles
Vos patients sont répartis en groupe A, groupe B et groupe C ? La tentation est forte de créer un onglet par groupe. C’est une mauvaise idée.
Le groupe n’est pas une feuille différente : c’est une variable. Tous les sujets doivent rester dans la même table, avec une colonne groupe qui contient par exemple A, B ou C.
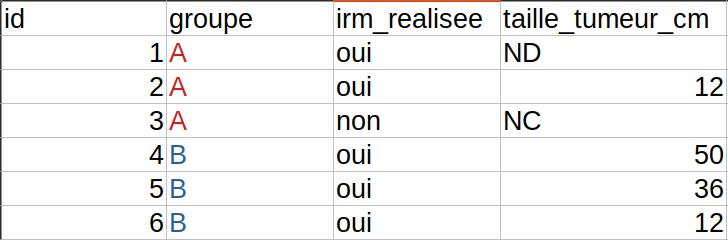
Si vous multipliez les onglets, vous risquez d’obtenir des colonnes légèrement différentes entre les groupes. L’import dans un logiciel statistique devient plus difficile, et les comparaisons deviennent moins fiables.
2. Utiliser la couleur comme information
Vous pouvez utiliser la couleur pour améliorer la lisibilité du fichier. En revanche, elle ne doit jamais porter une information nécessaire à l’analyse.
Erreur fréquente : colorer en rouge les sujets à exclure. Le problème est que la couleur n’est généralement pas importée comme une variable statistique.
La bonne solution consiste à créer une colonne dédiée :
| id_patient | groupe | exclusion_analyse | raison_exclusion |
|---|---|---|---|
| 001 | A | non | NC |
| 002 | B | oui | critère d’inclusion non respecté |
Vous pourrez ensuite filtrer les sujets exclus dans votre logiciel d’analyse ou dans TablR.
3. Mal gérer les dates
Les dates sont l’une des sources d’erreurs les plus fréquentes dans un tableur de recueil de thèse. Selon la configuration du logiciel, une date saisie en 02/10/2024 peut être interprétée comme le 2 octobre 2024 ou comme le 10 février 2024.
Le piège est que le tableur peut afficher une date plausible tout en ayant enregistré une valeur différente de celle que vous pensiez saisir.
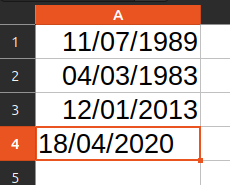
Changer ensuite le format d’affichage ne corrige pas toujours l’erreur initiale. Le tableur peut simplement afficher autrement une date déjà mal interprétée.
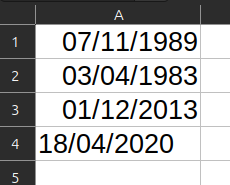
La solution la plus robuste est de paramétrer vos colonnes de dates avant le recueil et d’utiliser le format ISO : AAAA-MM-JJ, par exemple 2024-10-02. Ce format évite l’ambiguïté entre jours et mois.
4. Mettre plusieurs informations dans une même cellule
Une cellule doit contenir une seule information. Cette règle paraît simple, mais elle est souvent oubliée.
Une cellule peut contenir :
- une date ;
- une heure ;
- un nombre sans unité ;
- une modalité de catégorie ;
- une valeur binaire comme
oui/nonou1/0; - un code de valeur manquante.
Elle ne doit pas contenir plusieurs informations mélangées.
Exemples fréquents :
| Situation | Mauvais format | Meilleur format |
|---|---|---|
| Age pédiatrique | 2 mois 7 jours | age_jours = 67 |
| Antécédents | diabète, HTA, BPCO | une colonne par antécédent : diabete, hta, bpco |
| Traitements | metformine + insuline | variables séparées selon le besoin d’analyse |
| Motif d’hospitalisation | texte libre uniquement | variable codée, avec texte libre en complément si nécessaire |
Le texte libre peut être conservé quand il a une vraie utilité, mais il doit souvent être recodé ensuite pour être analysé. Si vous savez déjà quelles catégories vous intéressent, créez-les dès le départ.
5. Transformer trop tôt les variables quantitatives
Quand une variable est quantitative, recueillez sa valeur exacte. Vous pourrez toujours la transformer ensuite.
Exemple : pour l’âge, ne recueillez pas directement les classes [18-25[, [25-40[ et 40 ans et plus si vous avez accès à l’âge exact. Sinon, vous perdez la possibilité de calculer une moyenne, une médiane, un écart-type ou de changer les seuils plus tard.
La bonne logique :
- recueillir
age_annees = 37; - créer si besoin une variable dérivée
classe_age = 25-40; - documenter la règle de création de cette classe.
6. Nommer les variables sans convention
Les noms de variables doivent être courts, explicites et stables. Ils ne servent pas seulement à vous repérer : ils seront utilisés dans les exports, les analyses et parfois les scripts statistiques.
Évitez :
- les accents ;
- les apostrophes ;
- les espaces ;
- les signes de ponctuation ;
- les noms qui commencent par un chiffre ;
- les intitulés trop longs.
Deux conventions simples sont possibles :
| Convention | Exemple |
|---|---|
snake_case | duree_traitement_mois |
PascalCase | DureeTraitementMois |
Pour un tableur de recueil de thèse, snake_case est souvent le plus lisible : age_annees, sexe, groupe, date_inclusion, scanner_realise.
7. Coder les données sans dictionnaire
Il n’est pas obligatoire de remplacer toutes les modalités par des codes courts. Vous pouvez choisir entre deux approches.
Première option : conserver les libellés entiers, par exemple France, Allemagne, Espagne. C’est lisible, mais il faut être strict sur l’orthographe. France, FRANCE et france peuvent être interprétés comme trois modalités différentes.
Deuxième option : utiliser des codes, par exemple F, A, E ou 1, 2, 3. C’est rapide à saisir, mais impossible à relire correctement sans dictionnaire.
Si vous codez les données, gardez une feuille dictionnaire_variables dans le même fichier :
| variable | type | valeurs autorisées | signification |
|---|---|---|---|
| sexe | catégorielle | F, M | femme, homme |
| scanner_realise | binaire | 0, 1 | non, oui |
| groupe | catégorielle | A, B | prise en charge habituelle, intervention |
Cette feuille vous évitera beaucoup d’ambiguïtés au moment de l’analyse et de la rédaction des méthodes.
8. Laisser des cellules vides
Une cellule vide peut signifier plusieurs choses :
- la donnée n’a pas encore été cherchée ;
- la donnée est introuvable ;
- le sujet n’est pas concerné ;
- l’investigateur a oublié de saisir l’information.
Si tout reste vide, vous ne pourrez pas distinguer ces situations.
Prévoyez des codes explicites, par exemple :
| Code | Signification | Exemple |
|---|---|---|
ND | non disponible | résultat biologique absent du dossier |
NC | non concerné | diagnostic au scanner si aucun scanner n’a été réalisé |
NA | donnée manquante selon votre convention | information recherchée mais non retrouvée |
Choisissez une convention simple et gardez-la dans le dictionnaire des variables. Pour approfondir ce point, lisez l’article dédié aux valeurs manquantes dans un tableur.
Checklist avant de commencer le recueil
Avant de saisir les vraies données, vérifiez ces points.
| Point à vérifier | Question à se poser |
|---|---|
| Structure | Ai-je une ligne par sujet et une colonne par variable ? |
| Groupes | Les groupes sont-ils codés dans une colonne, et non dans plusieurs feuilles ? |
| Dates | Les dates sont-elles au format AAAA-MM-JJ ? |
| Unités | Les variables numériques sont-elles sans unité dans les cellules ? |
| Texte libre | Ai-je évité de mélanger plusieurs informations dans une cellule ? |
| Variables quantitatives | Ai-je conservé les valeurs exactes quand elles existent ? |
| Noms de variables | Les noms sont-ils courts, sans accents ni espaces ? |
| Codage | Les codes sont-ils documentés dans un dictionnaire ? |
| Valeurs manquantes | Les codes ND, NC ou équivalents sont-ils définis ? |
| Données de santé | Le stockage et les accès ont-ils été validés localement si nécessaire ? |
Sur le dernier point, ne tranchez pas seul si votre base contient des données de santé identifiantes ou pseudonymisées. L’article thèse de médecine et CNIL donne les premiers repères, mais les validations locales restent indispensables.
Tester son tableur avec quelques lignes fictives
Le meilleur test consiste à remplir 5 à 10 lignes fictives avant le vrai recueil.
Incluez volontairement :
- un sujet dans chaque groupe ;
- une donnée manquante ;
- une situation non concernée ;
- une date ;
- une variable binaire ;
- une variable quantitative ;
- une catégorie avec plusieurs modalités.
Ensuite, exportez ou importez le fichier dans l’outil que vous utiliserez pour les analyses. Vérifiez que :
- les variables numériques sont bien reconnues comme numériques ;
- les dates sont correctement interprétées ;
- les catégories ne sont pas dupliquées à cause d’une variation d’écriture ;
- les valeurs manquantes sont reconnues ou faciles à déclarer ;
- le fichier peut être utilisé sans correction manuelle lourde.
Vous pouvez aussi tester votre fichier dans TablR pour vérifier rapidement si le tableur est lisible et si les variables sont correctement reconnues.
En pratique : le tableur doit préparer l’analyse
Un bon tableur de recueil n’est pas celui qui ressemble le plus à un tableau de résultats. C’est celui qui permettra de passer du recueil aux analyses avec le moins d’ambiguïtés possible.
Avant de lancer le recueil, gardez cette règle : chaque cellule doit avoir une signification unique, chaque variable doit être documentée, et chaque choix de codage doit pouvoir être compris par quelqu’un d’autre que vous.
L’étape suivante consiste à décider comment vous traiterez les absences d’information. Commencez par l’article sur les valeurs manquantes dans un tableur, puis revenez à la section recueil de données si vous voulez vérifier l’ensemble du parcours.
Questions fréquentes
Comment structurer un tableur de recueil de thèse ?
La structure de base est une ligne par sujet et une colonne par variable. La première ligne doit contenir les noms de variables, avec des intitulés courts, stables et compréhensibles.
Faut-il coder les variables en 0/1 ?
Ce n’est pas obligatoire, mais c’est souvent utile pour les variables binaires. Si vous utilisez des codes, gardez toujours un dictionnaire clair qui explique la signification de chaque valeur.
Peut-on laisser des cellules vides dans un tableur de thèse ?
Il vaut mieux éviter les cellules vides pendant le recueil. Distinguez les données manquantes, les données non disponibles et les situations non concernées avec des codes explicites.
Quel format utiliser pour les dates ?
Le format ISO AAAA-MM-JJ est le plus sûr, car il évite les ambiguïtés entre formats français et américain. Il doit être paramétré avant le début de la saisie.
Faut-il faire relire son tableur avant le recueil ?
Oui, idéalement. Une relecture par l’encadrant, un méthodologiste ou un statisticien permet de repérer les variables inutilisables avant d’avoir saisi toute la base.