Créer un score prédictif dans une thèse de médecine : méthode et limites
Une méthode prudente pour construire, simplifier et présenter un score prédictif de thèse sans le confondre avec un outil clinique validé.
Créer un score prédictif peut donner une forme très concrète aux résultats d’une thèse de médecine. C’est tentant : au lieu de conclure seulement que plusieurs facteurs sont associés à un événement, vous proposez un outil qui estime un risque.
Mais c’est aussi une démarche méthodologique exigeante. Un score qui fonctionne bien sur vos propres données peut échouer sur d’autres patients. Dans une thèse, l’objectif le plus réaliste est souvent de construire et décrire un score exploratoire, puis d’expliquer clairement qu’il devra être validé avant tout usage clinique.
Ce qu’est vraiment un score prédictif
Un score prédictif estime la probabilité d’un événement à partir de plusieurs informations disponibles chez un patient ou dans un dossier.
Exemples :
- prédire le risque de complication postopératoire ;
- estimer la probabilité de réhospitalisation à 30 jours ;
- identifier les patients à risque de forme sévère ;
- prédire la réponse à un traitement.
Il faut distinguer trois niveaux :
| Niveau | Ce que cela signifie | Ce que vous pouvez raisonnablement affirmer |
|---|---|---|
| Modèle statistique | Une équation estime un risque à partir de variables | ”Nous avons construit un modèle prédictif.” |
| Score simplifié | Les coefficients sont transformés en points utilisables | ”Nous proposons un score dérivé du modèle.” |
| Outil clinique validé | Le score a été validé et son utilité a été évaluée | ”Le score peut aider une décision”, seulement si la validation le permet |
Dans une thèse, passer du premier au deuxième niveau est possible. Le troisième niveau demande beaucoup plus de travail.
Quand est-ce pertinent dans une thèse ?
Un score prédictif peut être pertinent si votre question porte naturellement sur un risque individuel.
Par exemple : “Quels facteurs permettent de prédire la survenue d’une complication ?” se prête mieux à un score que “Quels facteurs sont associés à la prescription d’un traitement ?”.
Avant de vous lancer, vérifiez ces points :
| Point à vérifier | Pourquoi c’est important |
|---|---|
| L’événement est clairement défini | Le score doit prédire une issue précise, pas une notion floue |
| La population est homogène | Un score construit sur des populations trop différentes prédit mal |
| Les variables sont disponibles avant l’événement | Un prédicteur mesuré après l’événement n’a pas de valeur prédictive utile |
| Le nombre d’événements est suffisant | Trop peu d’événements favorise le surapprentissage |
| Les données manquantes sont anticipées | Un score inutilisable pour une partie des patients perd vite son intérêt |
| Une validation est prévue | Sans validation, le score reste exploratoire |
Si vous êtes au début de votre projet, ce cadrage doit apparaître dans le protocole de thèse et dans le calcul du nombre de sujets nécessaires.
Étape 1 : définir l’événement à prédire
La première décision est de définir l’événement cible.
Pour une régression logistique, l’événement est binaire : oui/non, présent/absent, complication/pas de complication, décès/survie.
La définition doit préciser :
- la nature exacte de l’événement ;
- le délai de survenue ;
- la source de vérification ;
- les cas limites.
Exemple insuffisant : “complication postopératoire”.
Exemple plus exploitable : “survenue d’une complication postopératoire de grade Clavien-Dindo II ou plus dans les 30 jours suivant l’intervention, d’après le dossier médical”.
Cette précision compte autant pour l’analyse que pour la rédaction. Si votre événement est ambigu, le score le sera aussi.
Étape 2 : choisir les prédicteurs candidats
Un prédicteur est une variable utilisée pour estimer le risque. Il peut s’agir d’un âge, d’un antécédent, d’un score clinique, d’un résultat biologique ou d’une donnée d’imagerie.
Le choix des prédicteurs ne doit pas reposer uniquement sur une exploration automatique des p-values. Il doit s’appuyer sur :
- la question clinique ;
- la littérature ;
- la disponibilité réelle des données ;
- la fiabilité de la mesure ;
- la faisabilité d’utilisation du score.
Une variable très prédictive mais rarement disponible peut rendre le score impraticable. À l’inverse, une variable facile à recueillir mais trop imprécise peut ajouter du bruit.
Lorsque vous utilisez une variable catégorielle, il faut aussi définir une catégorie de référence. Par exemple, pour le tabagisme, vous pouvez choisir “non-fumeur” comme référence, puis comparer “sevré” et “actif” à cette référence.
Ce choix influence directement les coefficients du modèle et donc la construction du score.
Étape 3 : vérifier que l’effectif est compatible
La question n’est pas seulement “combien de patients ?”, mais surtout “combien d’événements ?”.
Un score prédictif cherche à apprendre la relation entre plusieurs variables et un événement. Si l’événement est rare, le modèle peut facilement s’adapter aux particularités de votre échantillon au lieu d’apprendre un signal généralisable. C’est le surapprentissage.
La règle historique des 10 événements par variable donne un ordre de grandeur, mais elle est trop simplifiée pour être utilisée seule. Les recommandations méthodologiques récentes insistent sur un calcul plus global, tenant compte notamment du nombre de prédicteurs, de la fréquence de l’événement et du risque de surapprentissage acceptable.
En pratique, pour une thèse :
- limitez le nombre de prédicteurs candidats ;
- évitez d’ajouter une variable “pour voir” ;
- justifiez les variables retenues ;
- discutez explicitement le risque de surapprentissage si l’effectif est limité.
Étape 4 : construire le modèle statistique
Pour un événement binaire, la méthode classique est la régression logistique multiple.
Elle permet d’estimer le poids de chaque prédicteur en tenant compte des autres variables du modèle. Le résultat brut n’est pas encore un score en points : c’est une équation.
Une forme simplifiée est :
logit(p) = intercept + β1 × X1 + β2 × X2 + β3 × X3
Le logit(p) n’est pas une probabilité. Pour obtenir une probabilité, il faut appliquer la transformation :
p = 1 / (1 + exp(-logit(p)))
C’est une différence importante. Dire que l’événement est prédit si l’équation est supérieure à 0,5 est incorrect : le seuil doit s’appliquer à une probabilité, et ce seuil doit être choisi selon le contexte clinique.
Ce qu’il vaut mieux éviter lors de la sélection des variables
Dans beaucoup de travaux, on commence par des analyses univariées, puis on conserve les variables avec une p-value inférieure à un seuil comme p < 0,20. Cette approche peut aider à explorer les données, mais elle ne doit pas devenir une règle automatique.
Elle pose plusieurs problèmes :
- une variable cliniquement importante peut être écartée par manque de puissance ;
- une variable instable peut être retenue par hasard ;
- le modèle final dépend beaucoup de l’échantillon ;
- les p-values ne mesurent pas la performance prédictive.
De la même façon, retirer successivement les variables parce que leur p-value devient “non significative” après ajustement peut produire un modèle fragile.
Une stratégie plus défendable consiste à définir un nombre limité de prédicteurs candidats avant l’analyse, à partir de la littérature et du raisonnement clinique, puis à expliquer clairement les éventuels choix statistiques secondaires.
Pour un modèle complexe, des méthodes comme la pénalisation ou le shrinkage peuvent être utiles, mais elles nécessitent un accompagnement statistique.
Si votre projet de score est déjà recueilli et que vous devez produire un modèle, des tableaux et une rédaction exploitable, la prestation d’analyse statistique pour thèse de médecine permet de cadrer ce périmètre.
Étape 5 : transformer le modèle en score
Une fois le modèle construit, vous pouvez transformer les coefficients en points.
L’idée est simple :
- récupérer les coefficients du modèle ;
- choisir une échelle de points ;
- convertir les coefficients en points ;
- vérifier que la simplification ne dégrade pas trop les performances ;
- définir comment interpréter le score.
Par exemple, un coefficient plus élevé donnera plus de points. Une catégorie de référence donnera souvent 0 point. Si les coefficients sont négatifs, il faut décider si le score doit augmenter avec le risque ou avec la protection.
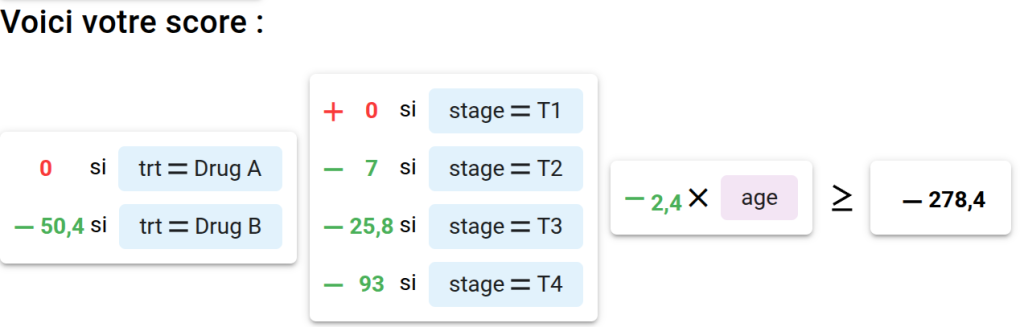
Cette transformation rend le score plus lisible, mais elle simplifie le modèle. Arrondir trop fortement les coefficients peut réduire la performance.
Étape 6 : évaluer le score
Un score ne se juge pas seulement parce que certaines variables sont associées à l’événement. Il faut évaluer sa performance prédictive.
Trois dimensions sont particulièrement importantes.
| Dimension | Question | Exemple d’indicateur |
|---|---|---|
| Discrimination | Le score classe-t-il correctement les patients à risque plus élevé ? | AUC, c-statistic |
| Calibration | Les probabilités prédites correspondent-elles aux fréquences observées ? | courbe de calibration, intercept et pente de calibration |
| Utilité clinique | Le score aide-t-il réellement une décision ? | seuils décisionnels, bénéfice net, impact attendu |
La discrimination est souvent la plus connue. Une AUC élevée peut être rassurante, mais elle ne suffit pas. Un score peut bien classer les patients tout en surestimant ou sous-estimant leur risque absolu.
La calibration est donc essentielle si vous annoncez des probabilités.
Étape 7 : valider le score
La validation répond à une question simple : le score fonctionne-t-il ailleurs que sur les données qui ont servi à le créer ?
On distingue notamment :
- la validation interne, réalisée à partir des données de développement, par exemple par bootstrap ou validation croisée ;
- la validation externe, réalisée sur une autre population, un autre centre ou une autre période.
Dans une thèse monocentrique avec effectif limité, la validation externe est rarement possible. Ce n’est pas bloquant, à condition de le dire clairement.
Vous pouvez écrire, par exemple :
Ce score doit être considéré comme exploratoire. Une validation externe sur une population indépendante sera nécessaire avant toute utilisation clinique.
Cette formulation est plus solide que de présenter le score comme un outil prêt à l’emploi.
Les recommandations TRIPOD et TRIPOD+AI rappellent l’importance de rapporter clairement la construction, la validation et les limites des modèles prédictifs. L’outil PROBAST peut aussi aider à identifier les risques de biais dans une étude de prédiction.
Comment présenter le score dans la thèse
Dans la méthode, décrivez :
- la définition de l’événement ;
- les prédicteurs candidats ;
- la gestion des données manquantes ;
- la méthode de modélisation ;
- la stratégie de sélection des variables ;
- la transformation des coefficients en points ;
- les méthodes d’évaluation et de validation.
Dans les résultats, présentez :
- les caractéristiques de l’échantillon ;
- le nombre d’événements ;
- les coefficients ou odds ratios du modèle ;
- le score final ;
- les performances du modèle ;
- les limites de validation.
Dans la discussion, insistez sur :
- le risque de surapprentissage ;
- la généralisation limitée si l’étude est monocentrique ;
- la nécessité d’une validation externe ;
- l’usage possible du score comme base de travail pour une étude ultérieure.
Si vous n’êtes pas à l’aise avec ces étapes, il vaut mieux demander un avis statistique tôt. L’article sur le choix entre faire ses statistiques soi-même ou demander de l’aide peut vous aider à décider.
Erreurs fréquentes
- Présenter un score non validé comme un outil clinique.
- Garder trop de prédicteurs pour trop peu d’événements.
- Sélectionner les variables uniquement sur les p-values.
- Confondre association et prédiction.
- Confondre logit et probabilité.
- Choisir automatiquement un seuil de probabilité à 0,5.
- Oublier la calibration.
- Ne pas expliquer comment les données manquantes ont été gérées.
- Reconstruire un score publié sans vérifier l’intercept et les définitions exactes.
Sources utiles
- TRIPOD Statement pour le reporting des modèles prédictifs.
- TRIPOD+AI 2024 pour les modèles prédictifs incluant l’intelligence artificielle.
- PROBAST pour l’évaluation du risque de biais des modèles prédictifs.
- Riley et al., BMJ 2020 pour l’estimation de la taille d’échantillon dans les modèles de prédiction.
En pratique
Créer un score prédictif peut être une très bonne idée de thèse si la question s’y prête, si l’effectif est compatible et si la validation est discutée honnêtement.
La bonne formulation n’est pas : “nous avons créé un score utilisable en pratique”.
Elle est plutôt : “nous avons construit un score exploratoire, dont les performances initiales sont décrites, et qui devra être validé sur une population indépendante”.
Pour approfondir la partie analyse, vous pouvez aussi consulter le guide sur le choix du logiciel de statistiques ou tester certaines analyses avec TablR.
Questions fréquentes
Peut-on créer un score prédictif dans une thèse de médecine ?
Oui, mais il faut le présenter avec prudence. Sans validation solide, il s’agit le plus souvent d’un score exploratoire, pas d’un outil utilisable directement en pratique clinique.
Combien de sujets faut-il pour créer un score prédictif ?
Il n’existe pas de nombre universel. Le besoin dépend du nombre d’événements, du nombre de prédicteurs, de la fréquence de l’événement et du niveau de surapprentissage acceptable.
Peut-on choisir les variables uniquement avec les p-values ?
Ce n’est pas conseillé. Les variables doivent être choisies à partir de la question clinique, de la littérature, de la qualité des données et du risque de surapprentissage.
Quelle différence entre discrimination et calibration ?
La discrimination mesure la capacité du score à classer les sujets selon leur risque. La calibration vérifie si les probabilités prédites correspondent aux risques réellement observés.
Peut-on utiliser un score créé dans une thèse en pratique clinique ?
Pas sans validation. Un score créé sur les données d’une seule thèse doit d’abord être évalué, idéalement sur d’autres données, avant d’être utilisé pour décider en pratique.