
Si votre travail de thèse consiste à identifier les facteurs associés à un événement (ex : décès, survenue d’une pathologie, rémission, etc), vous vous demandez peut-être comment créer un score prédictif ? On vous explique tout !
Pourquoi créer un score prédictif ?
Les scores prédictifs sont largement utilisés en médecine pour simplifier la prise de décision clinique en quantifiant le risque d’un événement à partir de différents facteurs. Quelques exemples fréquemment utilisés :
- score CHA2DS2VASC (désormais CHADSVA) pour prédire le risque embolique en cas de fibrillation atriale
- score de Wells pour prédire la probabilité de phlébite
Cet article présente une méthodologie rigoureuse pour la création d’un score prédictif en utilisant la régression logistique et explore plusieurs stratégies de pondération des coefficients.
1. Identifier l’événement à prédire et les facteurs de risque potentiels
La première étape consiste à définir une variable catégorielle à prédire (ex. : malade / sain) et à identifier les facteurs de risque potentiels en se basant sur la littérature et l’expertise clinique. Ces facteurs doivent être mesurables et pertinents pour la condition étudiée.
Vous devrez ensuite recueillir ces données dans votre échantillon. On considère qu’il faut au moins 10 événements par facteur étudié. Ainsi, si vous envisagez de créer un score comprenant 5 variables, il faudra au minimum 50 sujets présentant l’événement (et au moins autant sans l’événement). Ce n’est pas une règle absolue, mais elle donne une idée de l’ordre de grandeur de l’effectif nécessaire. Source :
Besoin d’aide pour préparer votre recueil ? Suivez nos conseils.
2. Sélection des facteurs de risque
Une fois votre recueil achevé, explorer l’association entre votre événement et chaque facteur de risque potentiel. Pour cela, réaliser des régressions logistiques simples (univariées).
Réalisez vos régressions logistiques en ligne avec TablR
Lorsque vous réalisez une régression avec des facteurs multinomiaux (c’est-à-dire des variables catégorielles avec plus de deux catégories), vous devrez choisir une valeur de référence. Ex : si vous recueillez le tabagisme comme non/actif/sevré et choisissez « non » comme référence, vous obtiendrez :
- un OR indiquant le surrisque à être fumeur (actifs vs non)
- un OR indiquant le surrisque au tabagisme sevré (sevré vs non)
Ce choix impactera la conception de votre score. Un sujet présentant la valeur de référence (ici non tabagique) marquera toujours 0 point. Des points seront donnés pour les autres valeurs (ex : +2 si sevré et +5 si actif).
Si vous aviez choisi « sevré » comme référence, vous pourriez par exemple avoir :
- non tabagique : -2 points
- sevré : 0 point
- tabagique actif : +3 points
Conservez les variables ayant une p-value faible (ex. : p < 0,20) et OR cliniquement pertinent. Quelques exemples :
- OR = 1,01, p = 0,01 -> significatif mais poids minime, peu d’intérêt dans un score
- OR = 5,00, p=0,10 -> non significatif, mais OR très important -> à conserver
Conservez également les éventuelles variables non significatives mais reconnues comme facteurs de risque dans la littérature.
Important : le fait de conserver ou abandonner un facteur est un choix subjectif. Quel que soit votre choix, veillez à exprimer clairement la méthode employée lors de la sélection de vos facteurs (dans votre paragraphe méthode).
3. Régression logistique multiple
Réalisez maintenant une régression logistique multiple sur les facteurs sélectionnés à l’étape 2. En ajustant, vous obtiendrez le poids de chaque facteur indépendamment les uns des autres. Observez alors les nouveaux OR et p-values. Si après ajustement certains facteurs n’ont plus d’intérêt (OR proche de 1, p-value élevée), retirez les et relancez votre régression.
Important : lorsque vous ajustez, le fait d’enlever ou ajouter un facteur peut impacter l’ensemble des OR et p-values. Vous devez donc relancer la régression à chaque modification.
4. Construction du score prédictif
Une fois votre régression logistique multiple réalisée, 2 solutions s’offrent à vous :
Utiliser notre outil dédié pour générer votre score
Accédez à notre outil de génération de scores et suivez les étapes :
- Importez votre tableur de données
- Précisez la variable à prédire (votre événement) ainsi que la ou les valeurs à prédire (ex : prédire si le grade du cancer vaudra III)
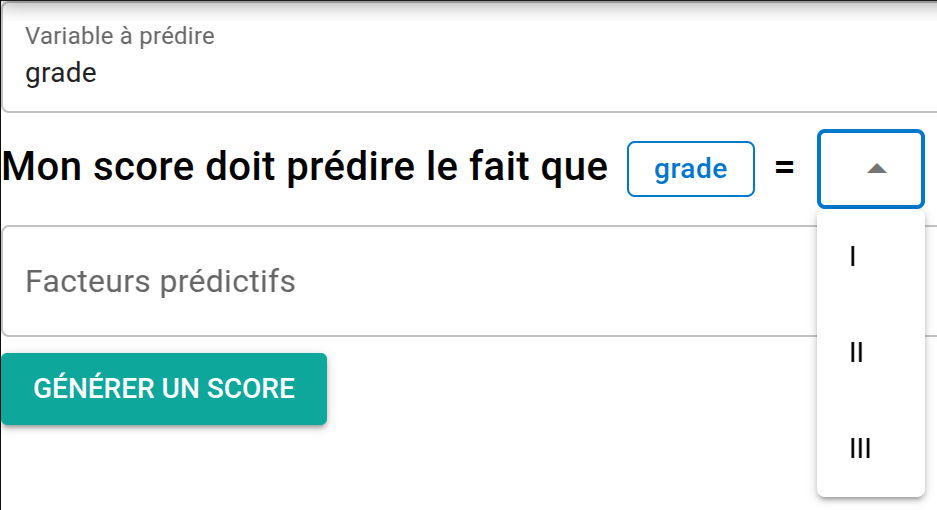
- Précisez vos facteurs prédictifs. Pour vos facteurs catégoriels, donnez la valeur à utiliser comme référence (celle qui vaudra 0 point dans votre score) :

- Cliquez sur Générer un score
Vous obtiendrez une proposition de score telle que ceci :
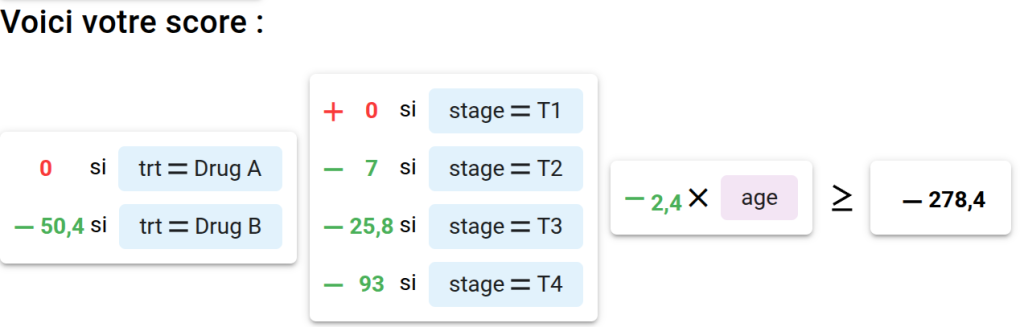
Ainsi qu’une interprétation :

Vous pourrez également jouer sur quelques paramètres pour rendre ce score plus pratique à utiliser :
- Décimales : modifiez le nombre de décimales à employer dans votre score. Réduire les décimales rend sa manipulation plus aisée mais fait cependant perdre en performance.
- Coefficient : Vous pouvez augmenter ou réduire les points de votre score en les multipliant par un coefficient global. Cela modifiera également le seuil de positivité de voter score.
- Inverser : Pratique lorsque la plupart des points associés à vos variables sont négatifs. Vous pouvez alors en inverser le sens. Exemple avec le score précédent :

Enfin, vous pourrez tester votre score en conditions réelles : renseignez les valeurs pour votre sujet et obtenez une prédiction :
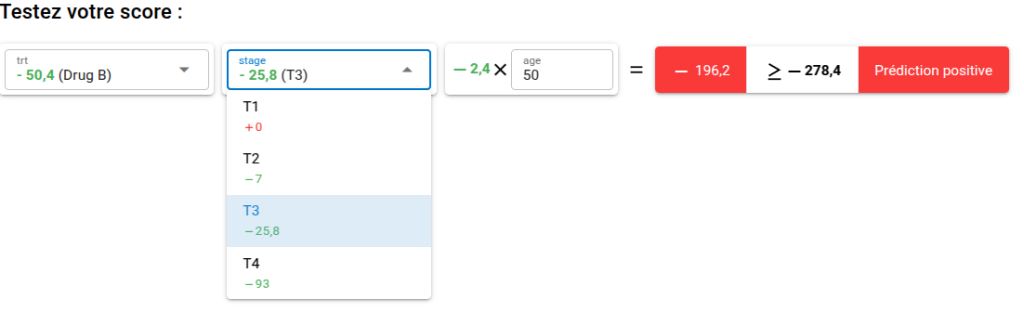
Vous souhaitez publier votre score en ligne ?
Contactez-nous !
Créer votre score à la main
Le résultat d’une régression logistique multiple peut s’écrire de la façon suivante :
Prédiction = Intercept + β1 x F1 + β2 x F2 + …
Avec :
- Intercept : une valeur numérique obtenue lors de votre régression logistique multiple
- βx les coefficients calculés par votre régression
- Fx vos facteurs (que vous remplacerez par les valeurs de votre sujet)
- Prédiction : une valeur numérique. On prédit que l’événement aura lieu si Prédiction > 0,5
Appliquer un logarithme népérien à vos OR. Pour chaque OR vous obtenez ainsi le coefficient β correspondant.
Réécrivez ensuite votre formule en remplaçant intercept et les coefficients β par les valeurs obtenues. Par exemple si je cherche à prédire le décès hospitalier sur la base de ces 3 facteurs ;
| Facteurs | Obésité (1=oui, 0=non) | Age (nombre entier) | SexeMasculin (1=oui, 0=non) |
| Coefficients β | 0,4 | 0,01 | 0,1 |
Avec Intercept = -0,1, Mon équation devient :
Prédiction = -0,1 + 0,4 x Obésité + 0,01 x Age + 0,1 x SexeMasculin
Quelque prédictions :
- homme obèse de 25 ans :
-0,1 + 0,4 x 1 + 0,01 x 25 + 0,1 x 1 = 0,65 -> la prédiction est positive (car supérieure à 0,5) - femme non obèse de 55 ans :
-0,1 + 0,4 x 0 + 0,01 x 55 + 0,1 x 0 = 0,45 -> la prédiction est négative (car inférieure à 0,5)
Ce score est néanmoins peu pratique à manipuler en pratique clinique du fait des décimales. Vous pouvez le transformer librement pour en faciliter l’usage. Par exemple :
Multiplier par 100 : -1 + 4 x Obésité + 1 x Age + 10 x SexeMasculin > 50
Faire disparaitre l’intercept (+1) : 4 x Obésité + 1 x Age + 10 x SexeMasculin > 51
Note : toutes ces étapes de simplification sont automatiquement proposées pa notre Outil de création de score en ligne
Bonus : créer un score prédictif à partir d’un article scientifique
La méthodologie décrite dans le paragraphe précédent n’a comme seul prérequis de connaitre les résultats d’une régression logistique. Dans un article scientifique explorant les facteurs associés à un événement, il est fréquent de retrouver les résultats de ces associations au travers d’une table résumant les résultats d’une régression logistique multiple. Vous pouvez alors utiliser ces informations pour recréer le score prédictif.
Veillez bien à ce que :
- les OR présentés soient issus d’une régression logistique. Si une autre méthode a été employée, cela ne marchera pas.
- La régression logistique doit être multivariée (synonyme parfois employé : multiple)
- Les variables ne doivent pas avoir été transformées. S’il est mentionné quelque chose comme les variables ont été log-transformées, les OR communiqués ne peuvent pas être exploités sans plus de précisions de la part des auteurs
- La valeur de l’Intercept doit être mentionnée
Ce dernier point est souvent manquant dans les articles. Dans ce cas, n’hésitez pas à contacter le corresponding author de l’article et à le lui demander en expliquant votre projet.
A noter : les OR présentés en article comprennent généralement 2 décimales. Les autres décimales étant arrondies, le score que vous obtiendrez pourra être légèrement moins performant que ce qui est annoncé par l’article.
Points importants
Les méthodes décrites ci-dessus vous permettrons de créer un score prédictif sur la base de vos données (ou de l’article source employé). Avant de le mettre en pratique, il est impératif de vérifier ses performances et sa validité. Ces deux points feront l’objet d’articles dédiés.
Un score prédictif basé sur des facteurs significativement associés à votre événement peut avoir une performance médiocre. Prenons un exemple : vous créez un score prédisant le risque de survenue de diabète de type 2 selon l’âge et la quantité de sucre moyenne ingérée quotidiennement. Ces deux facteurs seront très probablement associés à la survenue du diabète. Mais un score composé exclusivement de ces deux facteurs peinera à prédire de façon fiable la survenue du diabète. Il doit être complété par de nombreux autres facteurs pour devenir performant.
Sachez également que votre score peut être très performant lorsqu’il est appliqué sur vos données, mais présenter une performance bien moindre lorsqu’il est appliqué à d’autres populations. Pour cette raison, la performance de votre score doit être mesurée sur d’autre recueil et voir si ses performances sont généralisables.
Conclusion
Créer un score prédictif n’est donc pas très compliqué lorsque l’on a déjà effectué un travail d’identification de facteurs associés à un événement. Proposer un score en conclusion de votre travail est donc un vrai plus qui peut faire son effet. Il faudra cependant bien insister sur le besoin de faire valider ce score. Cela pourra faire l’objet de travaux ultérieurs.

